Optimism is an occupational hazard of programming; feedback is the treatment. -- Kent Beck |
Welcome to the third part of a series of N blog posts on using Dogen with ODB against an Oracle database. If you want more than the TL;DR, please read Part I and Part II. Otherwise, the story so far can be quickly summarised as follows: we got our Oracle Express database installed and set up by adding the required users; we then built the ODB libraries and installed the ODB compiler.
After this rather grand build up, we shall finally get to look at Dogen - just about. It now seems clear these series will have to be extended by at least one or two additional instalments in order to provide a vaguely sensible treatment of the material I had initially planned to cover. I wasn't expecting N to become so large, but - like every good software project - I'm now realising you can only estimate the size of the series properly once you've actually finished it. And to rub salt into the wounds, before we can proceed we must start by addressing some of the instructions in the previous posts which were not quite right.
Est Humanum Errare?
The first and foremost point in the errata agenda is concerned with
the additional Oracle packages we downloaded in Part I. When I had
originally checked my Oracle XE install, I did not find an include
directory, which led me to conclude that a separate download was
required for driver libraries and header files. I did find this state
of affairs somewhat unusual - but then again, it is Oracle we're
talking about here, so "unusual" is the default behaviour. As it turns
out, I was wrong; the header files are indeed part of the Oracle XE
install, just placed under a rather… shall we say, creative,
location: /u01/app/oracle/product/11.2.0/xe/rdbms/public. The
libraries are there too, under the slightly more conventionally named
lib directory.
This is quite an important find because the downloaded OCI driver has moved on to v12 whereas XE is still on v11. There is backwards compatibility, of course - and everything should work fine connecting a v12 client against an v11 database - but it does introduce an extra layer of complexity: you now need to make sure you do not simultaneously have both v11 and v12 shared objects in the path when linking and running or else you will start to get some strange warnings. As usual, we try our best to confuse only one issue at a time, so we need to make sure we are making use of v11 and purge all references to v12; this entails recompiling ODB's oracle support.
If you followed the instructions on Part II and you have already installed the ODB Oracle library, you'll need to remove it first:
rm /full/path/to/local/lib/libodb-oracle* /full/path/to/local/include/odb/oracle
Remember to replace /full/path/to/local with the path to your local
directory. Then, you can build by following the instructions as per
previous post, but with one crucial difference at configure time:
point to the Oracle XE directories instead of the external OCI driver
directories:
. /u01/app/oracle/product/11.2.0/xe/bin/oracle_env.sh LD_LIBRARY_PATH=/u01/app/oracle/product/11.2.0/xe/lib CPPFLAGS="-I/full/path/to/local/include -I/u01/app/oracle/product/11.2.0/xe/rdbms/public" LDFLAGS="-L/full/path/to/local/lib -L/u01/app/oracle/product/11.2.0/xe/lib" ./configure --prefix=/full/path/to/local
Again, replacing the paths accordingly. If all goes well, the end
result should be an ODB Oracle library that uses the OCI driver from
Oracle XE. You then just need to make sure you have executed
oracle_env.sh before running your binary, but don't worry too much
because I'll remind you later on. Whilst we're on the subject of
Oracle packages, it's worth mentioning that I did a minor update to
Part I: you didn't need to download SQLPlus separately either, as it
is also included in XE package. So, in conclusion, after a lot of
faffing, it turns out you can get away with just downloading XE and
nothing else.
The other minor alteration to what was laid out on the original posts
is that I removed the need for the basic database schema. In truth,
the entities placed in that schema were not adding a lot of value;
their use cases are already covered by the northwind schema, so I
removed the need for two schemas and collapsed them into one.
A final note - not quite an errata per se but still, something worthwhile mentioning. We didn't do a "proper" Oracle setup, so when you reboot your box you will find that the service is no longer running. You can easily restart it from the shell, logged in as root:
# cd /etc/init.d/ # ./oracle-xe start Starting oracle-xe (via systemctl): oracle-xe.service.
Notice that Debian is actually clever enough to integrate the Oracle scripts with systemd, so you can use the usual tools to find out more about this service:
# systemctl status oracle-xe
● oracle-xe.service - SYSV: This is a program that is responsible for taking care of
Loaded: loaded (/etc/init.d/oracle-xe; generated; vendor preset: enabled)
Active: active (exited) since Sun 2017-03-12 15:10:47 GMT; 6s ago
Docs: man:systemd-sysv-generator(8)
Process: 16761 ExecStart=/etc/init.d/oracle-xe start (code=exited, status=0/SUCCESS)
Mar 12 15:10:37 lorenz systemd[1]: Starting SYSV: This is a program that is responsible for taking c…e of...
Mar 12 15:10:37 lorenz oracle-xe[16761]: Starting Oracle Net Listener.
Mar 12 15:10:37 lorenz su[16772]: Successful su for oracle by root
Mar 12 15:10:37 lorenz su[16772]: + ??? root:oracle
Mar 12 15:10:37 lorenz su[16772]: pam_unix(su:session): session opened for user oracle by (uid=0)
Mar 12 15:10:39 lorenz oracle-xe[16761]: Starting Oracle Database 11g Express Edition instance.
Mar 12 15:10:39 lorenz su[16800]: Successful su for oracle by root
Mar 12 15:10:39 lorenz su[16800]: + ??? root:oracle
Mar 12 15:10:39 lorenz su[16800]: pam_unix(su:session): session opened for user oracle by (uid=0)
Mar 12 15:10:47 lorenz systemd[1]: Started SYSV: This is a program that is responsible for taking care of.
Hint: Some lines were ellipsized, use -l to show in full.
With all of this said, lets resume from where we left off.
Installing the Remaining Packages
We still have a number of packages to install, but fortunately the installation steps are easy enough so we'll cover them quickly in this section. Let's start with Dogen.
Dogen
Installing Dogen is fairly straightforward: we can just grab the latest release from BinTray:
As it happens, we must install v99 or above because we did a number of fixes to Dogen as a result of this series of articles; previous releases had shortcomings with their ODB support.
As expected, the setup is pretty standard-fare debian:
$ wget https://dl.bintray.com/domaindrivenconsulting/Dogen/0.99.0/dogen_0.99.0_amd64-applications.deb -O dogen_0.99.0_amd64-applications.deb $ sudo dpkg -i dogen_0.99.0_amd64-applications.deb [sudo] password for USER: Selecting previously unselected package dogen-applications. (Reading database ... 551550 files and directories currently installed.) Preparing to unpack dogen_0.99.0_amd64-applications.deb ... Unpacking dogen-applications (0.99.0) ... Setting up dogen-applications (0.99.0) ...
If all has gone according to plan, you should see something along the lines of:
$ dogen.knitter --version Dogen Knitter v0.99.0 Copyright (C) 2015-2017 Domain Driven Consulting Plc. Copyright (C) 2012-2015 Marco Craveiro. License: GPLv3 - GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>.
Dia
Dogen has multiple frontends - at the time of writing, JSON and Dia. We'll stick with Dia because of its visual nature, but keep in mind that what you can do with Dia you can also do with JSON.
A quick word on Dia for those not in the know, copied verbatim from its home page:
Dia is a GTK+ based diagram creation program for GNU/Linux, MacOS X, Unix, and Windows, and is released under the GPL license.
Dia is roughly inspired by the commercial Windows program 'Visio,' though more geared towards informal diagrams for casual use. It can be used to draw many different kinds of diagrams. It currently has special objects to help draw entity relationship diagrams, UML diagrams, flowcharts, network diagrams, and many other diagrams.
Dia does not change very often, which means any old version will do. You should be able to install dia straight off of package manager:
apt-get install dia
Other Dependencies
I had previously assumed Boost to be installed on Part II but - if nothing else, purely for the sake of completeness - here are the instructions to set it up, as well as CMake and Ninja. We will need these in order to build our application, but we won't dwell on them too much on them or else this series of posts would go on forever. Pretty much any recent version of Boost and CMake will do, so again we'll just stick to vanilla package manager:
# apt-get install cmake ninja-build libboost-all-dev
Mind you, you don't actually need the entirety of Boost for this exercise, but it's just easier this way.
Emacs and SQL Plus
Finally, a couple of lose notes which I might as well add here. If you wish to use SQLPlus from within Emacs - and you should, since the SQLi mode is just simply glorious - you can configure it to use our Oracle Express database quite easily:
(add-to-list 'exec-path "/u01/app/oracle/product/11.2.0/xe/bin") (setenv "PATH" (concat (getenv "PATH") ":/u01/app/oracle/product/11.2.0/xe/bin")) (setenv "ORACLE_HOME" "/u01/app/oracle/product/11.2.0/xe")
After this you will be able to start SQL Plus from Emacs with the
usual sql-oracle command. I recommend you to do at least a minimal
setup of SQL Plus too, to make it usable:
SQL> set linesize 8192 SQL> set pagesize 50000
Introducing Zango
After this excruciatingly long setup process, we can at long last start to create our very "simple" project. Simple in quotes because it ended up being a tad more complex than what was originally envisioned, so it was easier to create a GitHub repository for it. It would have been preferable to describe it from first principles, but then the commentary would literally go on for ever. A compromise had to be made.
In order to follow the remainder of this post please clone zango
from GitHub:
git clone git@github.com:DomainDrivenConsulting/zango.git
Zango is a very small Dogen project that builds with CMake. Here are some notes on the folder structure to help you navigate:
build/cmake: additional CMake modules that are not part of the standard CMake distribution. We need this for ODB, Oracle and Dogen.data: some application data that we will use to populate our database.projects: where all the code lives.projects/input_models: location of the Dogen models - in this case, we just have one. You could, of course, place it anywhere you'd like, but traditionally this is where they live.projects/northwind: code output of the Dogen model. This is the key project ofzango.projects/application: our little command line driver for the application.
Now, before we get to look at the code I'd like to first talk about Northwind and on the relationship between Dogen and ODB.
Northwind Schema
Microsoft makes the venerable Northwind database available in CodePlex, at this location. I found a useful description of the Northwind database here, which I quote:
Northwind Traders Access database is a sample database that shipped with Microsoft Office suite. The Northwind database contains the sales data for a fictitious company called Northwind Traders, which imports and exports specialty foods from around the world. You can use and experiment with Access with Northwind database while you're learning and develop ideas for Access.
If you really want a thorough introduction to Northwind, you could do worse than reading this paper: Adapting the Access Northwind Database to Support a Database Course. Having said that, for the purposes of this series we don't really need to dig that deep. In fact, I'll just present CodePlex's diagram with the tables and their relationships to give you an idea of the schema - without any further commentary - and that's more or less all that needs to be said about it:

Now, in theory, we could use this image to manually extract all the required information to create a Dia diagram that follows Dogen's conventions, code-generate that and Bob's your Uncle. However, in practice we have a problem: the CodePlex project only contains the SQL statements for Microsoft SQL Server. Part of the point of this exercise is to show that we can load real data from Oracle, rather than just generate random data, so it would be nice to load up the "real" Northwind data from their own tables. This would be more of an "end-to-end" test, as opposed to using ODB to generate the tables, and Dogen to generate random data which we can push to the database.
However, its not entirely trivial to convert T-SQL into Oracle SQL, and since this is supposed to be a "quick" project on the side - focusing on ODB and Dogen - I was keen on not spending time on unrelated activities such as SQL conversions. Fortunately, I found exactly what I was looking for: a series of posts from GeeksEngine entitled "Convert MS Access Northwind database to Oracle". For reference, these are as follows:
- How the data types in Access Northwind are converted to Oracle
- Building Oracle Northwind database objects
- Queries to generate aggregated data for Oracle Northwind database
If you don't care too much about the details, you can just look at the Oracle SQL statements, available here and copied across into the Zango project. I guess it's still worthwhile mentioning that GeeksEngine has reduced considerably the number of entities in the schema - for which they provide a rationale. Before we start an in-depth discussions into the merits of normalisation and de-normalisation and other DBA level topics, I have to stop you in your tracks. Please do not get too hung-up on the "quality" of the database schema of Northwind - either the Microsoft or the GeeksEngine one. The purpose of this exercise is merely to demonstrate how Dogen and ODB work together to provide an ORM solution. From this perspective, any vaguely realistic database schema is adequate - provided it allows us to test-drive all the features we're interested in. Whether you agree or not with the decisions the original creators of this schema made is a completely different matter, which is well beyond the scope of this series of posts.
Right, so now we need to setup our Northwind schema and populate it with data. For this you can open a SQL Plus session with user Northwind as explained previously and then run in the SQL script:
@/path/to/zango/data/Oracle-Northwind.sql
Replacing /path/to with the full path to your Zango checkout. This
executes the GeeksEngine script against your local Oracle XE
database. If all has gone well, you should now have a whole load of
tables and data. You can sanity-check the setup by running the
following SQL:
SQL> select table_name from all_tables where owner = 'NORTHWIND';
TABLE_NAME
------------------------------
ORDER_DETAILS
CATEGORIES
CUSTOMERS
EMPLOYEES
SUPPLIERS
SHIPPERS
PRODUCTS
ORDERS
8 rows selected.
SQL> select employee_id, firstname, lastname from employees where rownum <3;
EMPLOYEE_ID FIRSTNAME LASTNAME
----------- ---------- --------------------
1 Nancy Davolio
2 Andrew Fuller
Now then, let's model these entities in Dogen.
The Dogen Model for Northwind
Before we proceed, I'm afraid I must make yet another disclaimer: a proper explanation on how to use Dia (and UML in general) is outside the scope of these articles, so you'll see me hand-waving quite a lot. Hopefully the diagrams are sufficiently self-explanatory for you to get the idea.
The process of modeling is simply to take the entities of the
GeeksEngine SQL schema and to model them in Dia, following Dogen's
conventions: each SQL type is converted to what we deemed to be the
closest C++ type. You can open the diagram from the folder
projects/input_models/northwind.dia, but if you haven't got it
handy, here's a screenshot of most of the UML model:
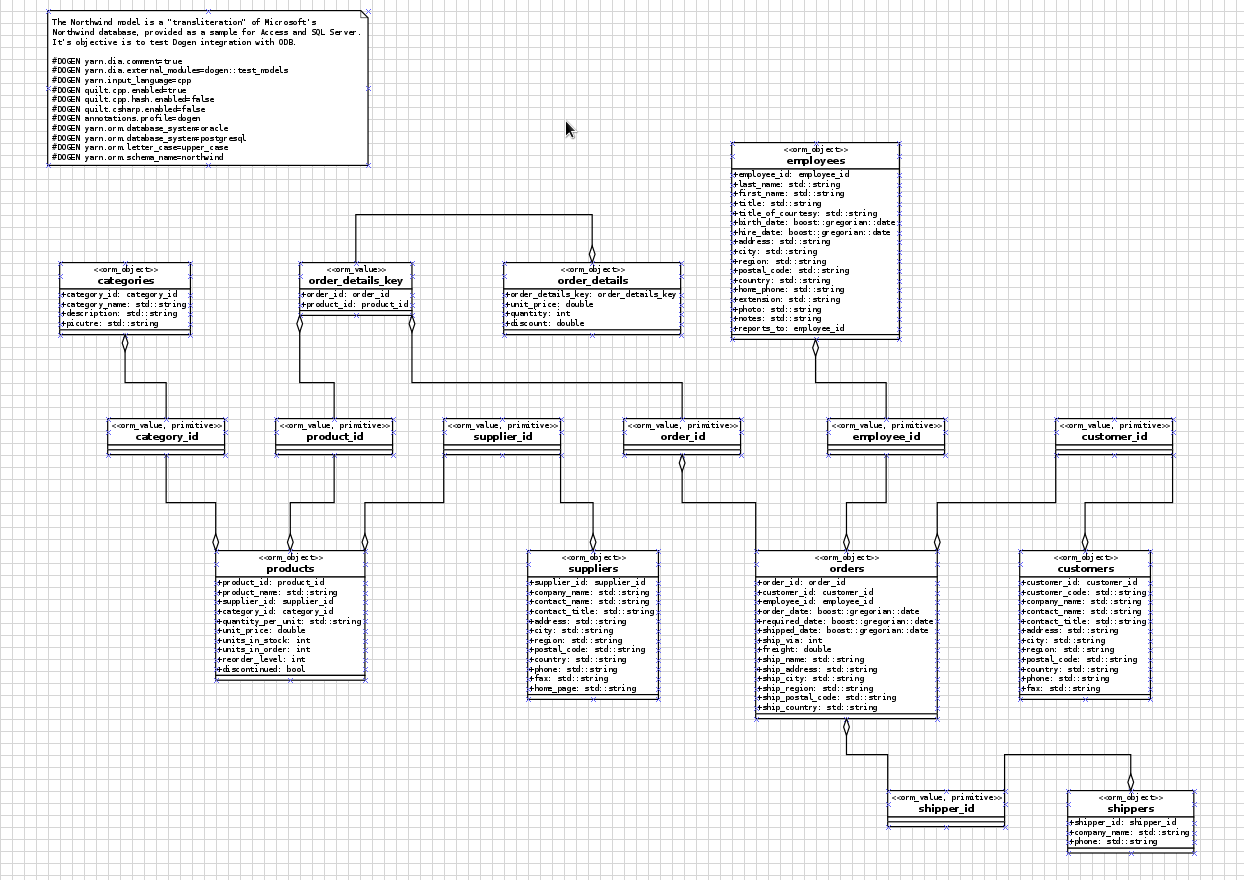
The first point of note in that diagram is - if you pardon the pun - the UML note.

Figure 1: UML Note from northwind model.
This configuration is quite important so we'll discuss it a bit more
detail. All lines starting with #DOGEN are an extension mechanism
used to supply meta-data into Dogen. First, lets have a very quick
look at the model's more "general settings":
yarn.dia.comment: this is a special command that tells Dogen to use this UML note as the source code comments for the namespace of the model (i.e.northwind). Thus the text "The Northwind model is a…" will become part of a doxygen comment for the namespace.yarn.dia.external_modules: this places all types into the top-level namespacenorthwind.yarn.input_language: the notation for types used in this model is C++. We won't delve on this too much, but just keep in mind that Dogen supports both C++ and C#.quilt.cpp.enabled: as we are using C++, we must enable it.quilt.cpp.hash.enabled: we not require this feature for the purposes of this exercise.quilt.csharp.enabled: As this is a C++-only model, we will disable C#.annotations.profile: Do not worry too much about this knob, it just sets a lot of default options for this project such as copyright notices and so forth.
As promised, you won't fail to notice we hand-waved quite a lot on the description of these settings. It is very difficult to explain them properly them without giving the reader an immense amount of context about Dogen. This, of course, needs to be done - particularly since we haven't really spent the required time updating the manual. However, in the interest of keeping this series of posts somewhat focused on ODB and ORM, we'll just leave it at that, with a promise to create Dogen-specific posts on them.
Talking about ORM, the next batch of settings is exactly related to that.
yarn.orm.database_system: here, we're stating that we're interested in bothoracleandpostgresqldatabases.yarn.orm.letter_case: this sets the "case" to use for all identifiers; eitherupper_caseorlower_case. So if you chooseupper_case, all your table names will be in upper case and vice-versa. This applies to all columns and object names on the entirety of this model (e.g.customersbecomesCUSTOMERSand so forth).yarn.orm.schema_name: finally we set the schema name tonorthwind. Remember that we are in upper case, so the name becomesNORTHWIND.
In addition to the meta-data, the second point worth noticing is that
there is a large overlap between C++ classes and the entities in the
original diagram. For example, we have customers, suppliers,
employees and so forth - the Object-Relational Mapping is very
"linear". This is a characteristic of the Dogen approach to ORM, but
you do not necessarily need to use ODB in this manner; we discuss this
in the next section.
If one is to look at a properties of a few attributes in more detail,
one can see additional Dogen meta-data. Take customer_id in the
customers class:
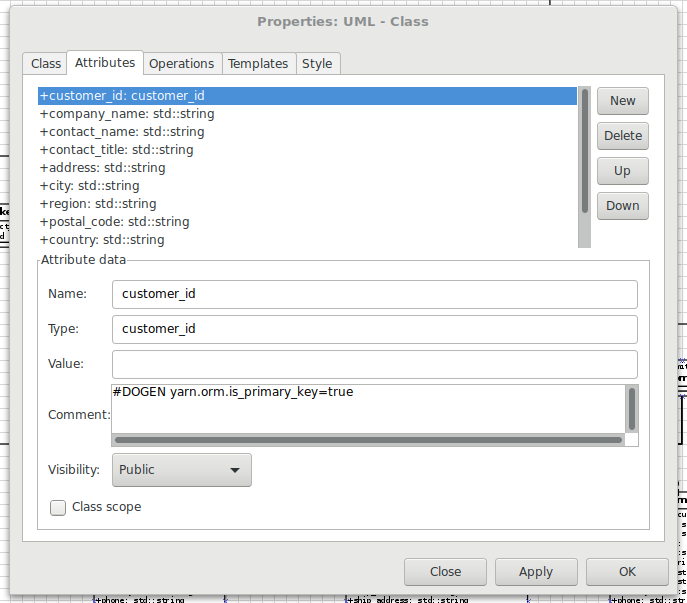
Figure 2: Properties of customerid in the customer class.
The setting yarn.orm.is_primary_key tells Dogen that this attribute
is the primary key of the table. Note that we did not use an int as
the type of customer_id but instead made use of a Dogen feature
called "primitives". Primitives are simple wrappers around builtins
and "core" types such as std::string, intended to have little or no
overhead after the compiler is done with them. They are useful when
you want to use domain concepts to clarify intent. For example,
primitives help making it obvious when you try to use a customer_id
when a supplier_id was called for. It's also worth noticing that
customer_id makes use of yarn.orm.is_nullable - settable to true
or false. It results in Dogen telling ODB if a column can be NULL
or not.
As we stated, each of the attributes of these classes has the closest
C++ type we could find that maps to the SQL type used in the database
schema. Of course, different developers can make different choices for
these types. For example, were we to store the picture data rather
than a path to the picture as GeeksEngine decided to do, we would use
a std::vector<char> instead of a std::string. In that case, we'd
have to perform some additional mapping too:
#DOGEN yarn.orm.type_override=postgresql,BYTEA #DOGEN yarn.orm.type_override=oracle,BLOB
This tells Dogen about the mapping of the attribute's type to the SQL type. Dogen then conveys this information to ODB.
Dogen's ORM support is still quite young - literally a couple of
sprints old - so there will be cases where you may need to perform
some customisation which is not yet available in its meta-model. In
these cases, you can bypass Dogen and make use of ODB pragmas
directly. As an example, GeeksEngine Oracle schema named a few columns
in Employees without underscores such as FIRSTNAME and
LASTNAME. We want the C++ classes to have the correct names
(e.g. first_name, last_name, etc) so we simply tell ODB that these
columns have different names in the database. Take last name for
example:
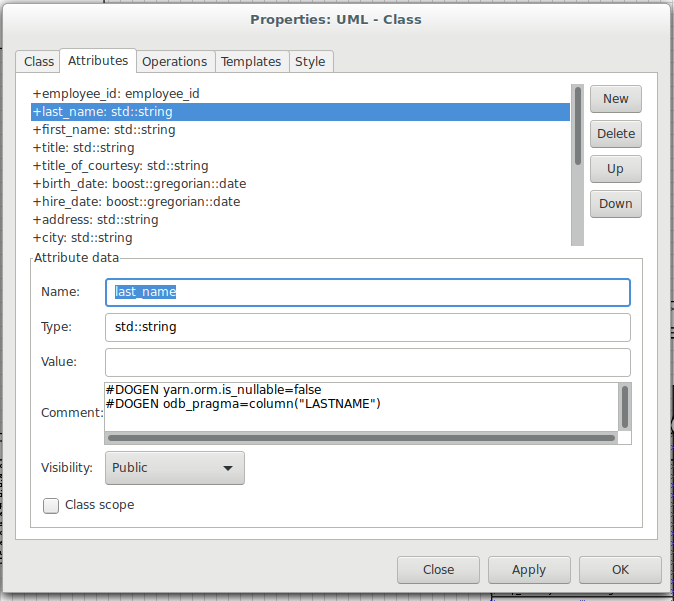
Figure 3: Properties of last name in the employee class.
A final note on composite keys. Predictably, Dogen follows the ODB
approach - in that primary keys that have more than one column must be
expressed as a class on its own right. In northwind, we use the
postfix _key for these class names in order to make them easier to
identify - e.g. order_details_key. You won't fail to notice that
this class has the flag yarn.orm.is_value set. It tells Dogen - and,
by extension, ODB - that it is not really a full-blown type, which
would map it to a table, but instead should be treated like other
value types such as std::string.
Interlude: Dogen with ODB vs Plain ODB
"The technical minutiae is all well and good", the inquisitive reader will say, "but why Dogen and ODB? Why add yet another layer of indirection when one can just use ODB?" Indeed, it may be puzzling for there to be a need for a code-generator which generates code for another code-generator. "Turtles all the way down" and "We over-engineered it yet again", the crowd chants from the terraces.
Let me attempt to address some of these concerns.
First, it is important to understand the argument we're trying to make here: Dogen models benefit greatly from ODB, but its not necessarily the case that all ODB users benefit from Dogen. Let's start with a classic ODB use case, which is to take an existing code base and add ORM support to it. In this scenario it makes no sense to introduce Dogen; after all, ODB requires only small changes to the original source code and has the ability to parse very complex C++. And, of course, using ODB in this manner also allows one to deal with impedance mismatches between the relational model and the object model of your domain.
Dogen, on the other hand, exists mainly to support Model Driven
Software Development (MDSD), so the modeling process is the
driver. This means that one is expected to start with a Dogen model,
and to use the traditional MDSD techniques for the management of the
life-cycle of your model - and eventually for the generation of
entire software product lines. Of course, you need not buy into the
whole MDSD sales pitch in order to make use of Dogen, but you should
at least understand it in this context. At a bare minimum, it requires
you to think in terms of Domain Models - as Domain Driven Development
defines them - and then in terms of "classes of features" required by
the elements of your domain. These we call "facets" in Dogen
parlance. There are many such facets like io, which is the ability
to dump an object's state into a C++ stream - at present using JSON
notation - or serialization which is the ability to serialise an
object using Boost serialisation. It is in this context that ODB
enters the Dogen world. We could, of course, generate ORM mappings
(and SQL) directly from Dogen. But given what we've seen from ODB, it
seems this would be a very large project - or, conversely, we'd have
very poor support, not dealing with a great number of corner cases. By
generating the very minimal and very non-intrusive code that ODB
needs, we benefit from the years of experience accumulated in this
tool whilst at the same time making life easier for Dogen users.
Of course, as with all engineering trade-offs, this one is not without
its disadvantages. When things do go wrong you now have more moving
parts to go through when root-causing: was it an error in the diagram,
or was it Dogen, or was it the mapping between Dogen and ODB or was it
ODB? Fortunately, I found that this situation is minimised by the way
in which you end up using Dogen. For instance, all generated code can
be version-controlled, so you can look at the ODB input files
generated by Dogen and observe how they change with changes in the
Dogen model. The Dogen ODB files should also look very much like
regular hand-crafted ODB files - making use of pragmas and so
forth - and you are also required to run ODB manually against
them. Thus, in practice, I have found troubleshooting straightforward
enough that the layers of indirection end up not constituting a real
problem.
Finally, its worth pointing out that the Domain Models Dogen generates
have a fairly straightforward shape to them, making the ODB mapping a
lot more trivial that "general" C++ code would have. It is because of
this that we have orm parameters in Dogen, which can expand to
multiple ODB pragmas - the user should not need to worry about that
expansion.
Conclusion
This part is already becoming quite large, so I'm afraid we need to stop it here and continue on Part IV. However, we have managed to address a few of the mistakes of the Oracle setup of previous parts, introduced the remaining applications that we need to install and then discussed Northwind - both in terms of its original intent and also in terms of the Dogen objectives. Finally we provided an explanation of how Dogen and ODB fit together in a tooling ecosystem.

No comments:
Post a Comment