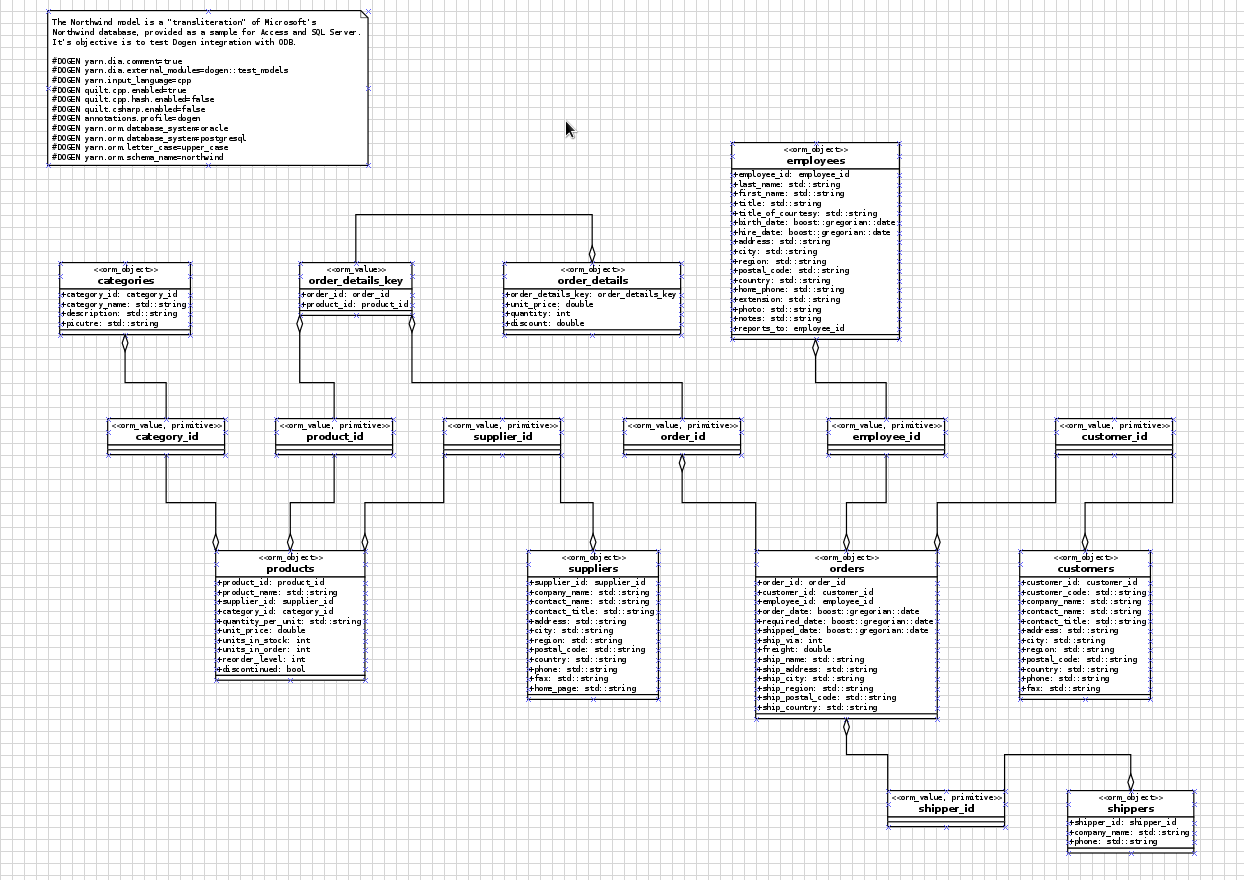
So, dear reader, we meet again for the fourth and final instalment of our series of posts on using Dogen with ODB! And if you missed an episode - unlikely as it may be - well, fear not for you can always catch up! Here are the links: Part I, Part II and Part III. But, if you are too lazy and need a summary: all we've done thus far is to install and setup an Oracle Express database, populate it with a schema (and data) and finally code-generate an ORM model with Dogen and ODB.
I guess it would not be entirely unfair to describe our adventure thus far as a prelude; if nothing else, it was a character building experience. But now we can finally enjoy the code.
Building Zango
Assuming you have checked out zango as described in Part III and you
are sitting on its containing directory, you can "configure" the
project fairly simply:
$ . /u01/app/oracle/product/11.2.0/xe/bin/oracle_env.sh $ cd zango $ git pull origin master $ cd build $ mkdir output $ cd output $ CMAKE_INCLUDE_PATH=/full/path/to/local/include CMAKE_LIBRARY_PATH=/full/path/to/local/lib cmake ../.. -G Ninja -- The C compiler identification is GNU 6.3.0 <lots of CMake output> -- Generating done -- Build files have been written to: /path/to/zango/build/output
As always, do not forget to replace /full/path/to/local with your
path to the directory containing the ODB libraries. If all has gone
according to plan, CMake should have found ODB, Boost, Dogen and all
other dependencies we have carefully and painstakingly setup in the
previous three parts.
Once the configuration is done, you can fire up Ninja to build:
$ ninja -j5 [1/100] Building CXX object projects/northwind/src/CMakeFiles/northwind.dir/io/category_id_io.cpp.o <lots of Ninja output> [98/100] Linking CXX static library projects/northwind/src/libzango.northwind.a [99/100] Building CXX object CMakeFiles/application.dir/projects/application/main.cpp.o [100/100] Linking CXX executable application
That was easy! But what exactly have we just built?
The "Application"
We've created a really simple application to test drive the northwind model. Of course, this is really not how your production code should look like, but it'll do just fine for our purposes. We shall start by reading a password from the command line and then we use it to instantiate our Oracle database:
const std::string password(argv[1]);
using odb::oracle::database;
std::unique_ptr<database>
db(new database("northwind", password, "XE", "localhost", 1521));
We then use this database to read all available customers:
std::list<zango::northwind::customers>
load_customers(odb::oracle::database& db) {
odb::oracle::transaction t(db.begin());
std::list<zango::northwind::customers> r;
auto rs(db.query<zango::northwind::customers>());
for (auto i(rs.begin ()); i != rs.end (); ++i)
r.push_back(*i);
return r;
}
Please note that this is a straightforward use of the ODB API, but barely scratches the surface of what ODB can do. ODB supports all sorts of weird and wonderful things, including fairly complex queries and other great features. If you'd like more details on how to use ODB, you should read its manual: C++ Object Persistence with ODB. It's extremely comprehensive and very well written.
Once we have the customers in memory, we can start to do things with them. We can for example serialise them to a Boost serialisation binary archive and read them back out:
boost::filesystem::path file("a_file.bin");
{
boost::filesystem::ofstream os(file);
boost::archive::binary_oarchive oa(os);
oa << customers;
}
std::cout << "Wrote customers to file: "
<< file.generic_string() << std::endl;
std::list<zango::northwind::customers> customers_from_file;
{
boost::filesystem::ifstream is(file);
boost::archive::binary_iarchive ia(is);
ia >> customers_from_file;
}
This is where hopefully you should start to see the advantages of Dogen: without writing any code, we have full serialisation support to all classes in the model - in addition to ODB support, of course.
Another very useful feature is to dump objects into a stream:
for (const auto& c : customers_from_file)
std::cout << "Customer: " << c << std::endl;
The objects are written in JSON, making it easy to post-process the output with JSON tools such as JQ, resulting in a nicely formatted string:
{
"__type__": "zango::northwind::customers",
"customer_id": {
"__type__": "zango::northwind::customer_id",
"value": 90
},
"customer_code": "WILMK",
"company_name": "Wilman Kala",
"contact_name": "Matti Karttunen",
"contact_title": "Owner/Marketing Assistant",
"address": "Keskuskatu 45",
"city": "Helsinki",
"region": "",
"postal_code": "21240",
"country": "Finland",
"phone": "90-224 8858",
"fax": "90-224 8858"
}
Dogen supports dumping arbitrarily-nested graphs, so it's great for logging program state as you go along. We make extensive use of this in Dogen, since - of course - we use Dogen to develop Dogen. Whilst this has proven invaluable, we have also hit some limits. For example, sometimes you may bump into really large and complex objects and JQ just won't cut it. But the great thing is that you can always dump the JSON into PostgreSQL - very easily indeed, given the ODB support - and then run queries on the object using the power of JSONB. With a tiny bit more bother you can also dump the objects into MongoDB.
However, with all of this said, it is also important to notice that we do not support proper JSON serialisation in Dogen at the moment. This will be added Real-Soon-Now, as we have a real need for it in production, but its not there yet. At present all you have is this debug-dumping of objects into streams which happens to be JSON. It is not real JSON serialisation. Real JSON support is very high on our priority list though, so expect it to land in the next few sprints.
Another useful Dogen feature is test data generation. This can be handy for performance testing, for example. Let's say we want to generate ~10K customers and see how Oracle fares:
std::vector<zango::northwind::customers> generate_customers() {
std::vector<zango::northwind::customers> r;
const auto total(10 * 1000);
r.reserve(total);
zango::northwind::customers_generator g;
for (int i = 0; i < total; ++i) {
const auto c(g());
if (i > 100)
r.push_back(g());
}
return r;
}
Note that we skipped the first hundred customers just to avoid clashes
with the customer_id primary key. Now, thanks to the magic of ODB we
can easily push this data into the database:
void save_customers(odb::oracle::database& db,
const std::vector<zango::northwind::customers>& customers) {
odb::transaction t(db.begin());
for (const auto c : customers)
db.persist(c);
t.commit();
}
Et voilá, we have lots of customers in the database now:
SQL> select count(1) from customers;
COUNT(1)
----------
9990
To be totally honest, this exercise revealed a shortcoming in Dogen: since it does not know of the size of fields on the database, the generated test data may in some cases be too big to fit the database fields:
Saving customers... terminate called after throwing an instance of 'odb::oracle::database_exception' what(): 12899: ORA-12899: value too large for column "NORTHWIND"."CUSTOMERS"."CUSTOMER_CODE" (actual: 6, maximum: 5)
I solved this problem with a quick hack for this article (by removing the prefix used in the test data) but a proper fix is now sitting in Dogen's product backlog for implementation in the near future.
Finally, just for giggles, I decided to push the data we read from Oracle into Redis, an in-memory cache that seems to be all the rage amongst the Cool-Kid community. To keep things simple, I used the C API provided by hiredis. Of course, if this was the real world, I would have used one of the many c++ clients for Redis such as redis-cplusplus-client or cpp redis. As it was, I could not find any Debian packages for them, so I'll just have to pretend I know C. Since I'm not much of a C programmer, I decided to do a very bad copy and paste job from this Stack Overflow article. The result was this beauty (forgive me in advance, C programmers):
redisContext *c;
redisReply *reply;
const char *hostname = "localhost";
int port = 6379;
struct timeval timeout = { 1, 500000 }; // 1.5 seconds
c = redisConnectWithTimeout(hostname, port, timeout);
if (c == NULL || c->err) {
if (c) {
std::cerr << "Connection error: " << c->errstr << std::endl;
redisFree(c);
} else {
std::cerr << "Connection error: can't allocate redis context"
<< std::endl;
}
return 1;
}
std::ostringstream os;
boost::archive::binary_oarchive oa(os);
oa << customers;
const auto value(os.str());
const std::string key("customers");
reply = (redisReply*)redisCommand(c, "SET %b %b", key.c_str(),
(size_t) key.size(), value.c_str(), (size_t) value.size());
if (!reply)
return REDIS_ERR;
freeReplyObject(reply);
reply = (redisReply*)redisCommand(c, "GET %b", key.c_str(),
(size_t) key.size());
if (!reply)
return REDIS_ERR;
if ( reply->type != REDIS_REPLY_STRING ) {
std::cerr << "ERROR: " << reply->str << std::endl;
return 1;
}
const std::string redis_value(reply->str, reply->len);
std::istringstream is(redis_value);
std::list<zango::northwind::customers> customers_from_redis;
boost::archive::binary_iarchive ia(is);
ia >> customers_from_redis;
std::cout << "Read from redis: " << customers_from_redis.size()
<< std::endl;
std::cout << "Front customer (redis): "
<< customers_from_redis.front() << std::endl;
freeReplyObject(reply);
And it actually works. Here's the output, with manual formatting of JSON:
Read from redis: 91
Front customer (redis): {
"__type__": "zango::northwind::customers",
"customer_id": {
"__type__": "zango::northwind::customer_id",
"value": 1
},
"customer_code": "ALFKI",
"company_name": "Alfreds Futterkiste",
"contact_name": "Maria Anders",
"contact_title": "Sales Representative",
"address": "Obere Str. 57",
"city": "Berlin",
"region": "",
"postal_code": "12209",
"country": "Germany",
"phone": "030-0074321",
"fax": "030-0076545"
}
As you can hopefully see, in very few lines of code we managed to connect to a RDBMS, read some data, push it into a stream, read it and write into Boost Serialization archives and push it into and out of Redis. All this in fairly efficient C++ code (and some very dodgy C code, but we'll keep that one quiet).
A final note on the CMake targets. Zango comes with a couple of targets for Dogen and ODB:
knit_northwindgenerates the Dogen code from the model.odb_northwindruns ODB against the Dogen model, generating the ODB sources.
The ODB target is added automatically by Dogen. The Dogen target was added manually by yours truly, and it is considered good practice to have one such target when you use Dogen so that other Dogen users know how to generate your models. You can, of course, name it what you like, but in the interest of making everyone's life easier its best if you follow the convention.
Oracle and Bulk Fetching
Whilst I was playing around with ODB and Oracle, I noticed a slight problem: there is no bulk fetch support in the ODB Oracle wrappers at present; it works for other scenarios, but not for selects. I reported this to the main ODB mailing list here. By the by, the ODB community is very friendly and their mailing list is a very responsive place to chat about ODB issues.
Anyway, so you can have an idea of this problem, here's a fetch of our generated customers without prefetch support:
<snip> Generating customers... Generated customers. Size: 9899 Saving customers... Saved customers. Read generated customers. Size: 9990 time (ms): 263.449 <snip>
Remember the 263.449 for a moment. Now say you delete all rows we
generated:
delete from customers where customer_id > 100;
Then, say you apply to libodb-oracle the hastily-hacked patch I
mentioned in that mailing list thread. Of course, I am hand-waving
here greatly, as you need to rebuild the library, install the
binaries, rebuild zango, etc, but you get the gist. At any rate,
here's the patch, hard-coding an unscientifically-obtained-prefetch of
5K rows:
--- original_statement.txt 2017-02-09 15:45:56.585765500 +0000
+++ statement.cxx 2017-02-13 10:18:28.447916100 +0000
@@ -1574,18 +1574,29 @@
OCIError* err (conn_.error_handle ());
+ const int prefetchSize(5000);
+ sword r = OCIAttrSet (stmt_,
+ OCI_HTYPE_STMT,
+ (void*)&prefetchSize,
+ sizeof(int),
+ OCI_ATTR_PREFETCH_ROWS,
+ err);
+
+ if (r == OCI_ERROR || r == OCI_INVALID_HANDLE)
+ translate_error (err, r);
+
// @@ Retrieve a single row into the already bound output buffers as an
// optimization? This will avoid multiple server round-trips in the case
// of a single object load.
//
- sword r (OCIStmtExecute (conn_.handle (),
+ r = OCIStmtExecute (conn_.handle (),
stmt_,
err,
0,
0,
0,
0,
- OCI_DEFAULT));
+ OCI_DEFAULT);
if (r == OCI_ERROR || r == OCI_INVALID_HANDLE)
translate_error (conn_, r);
And now re-run the command:
Generated customers. Size: 9899 Saving customers... Saved customers. Read generated customers. Size: 9990 time (ms): 40.85
Magic! We're down to 40.85. Now that I have a proper setup, I am
going to start working on upstreaming this patch, so that ODB can
expose the fetch configuration for fetching in a similar manner it
already does for other purposes. If you are interested in the gory
technical details, have a look at Boris' reply.
Conclusion
Hopefully this concluding part gave you an idea of why you might want to use Dogen with ODB for your modeling needs. Sadly, its not easy to frame the discussion adequately, so that you have all the required context in order to place these two tools in the continuum of tooling; but I'm hoping this series of articles was useful to at least help you setup Oracle Express in Debian and get an idea of what you can do with these two tools.